Structured rules, faster AI coding.
Make development faster and more efficient with tailored instructions.
Overview
RulesForAI is a developer-focused web product that helps users create Rules and Skills for AI coding assistants.
The core value is consistency: instead of relying on ad-hoc prompts, users generate standardized instructions that are easier to reuse across projects.
I owned the full lifecycle: product direction, UX, architecture, full-stack implementation, and ongoing iteration.
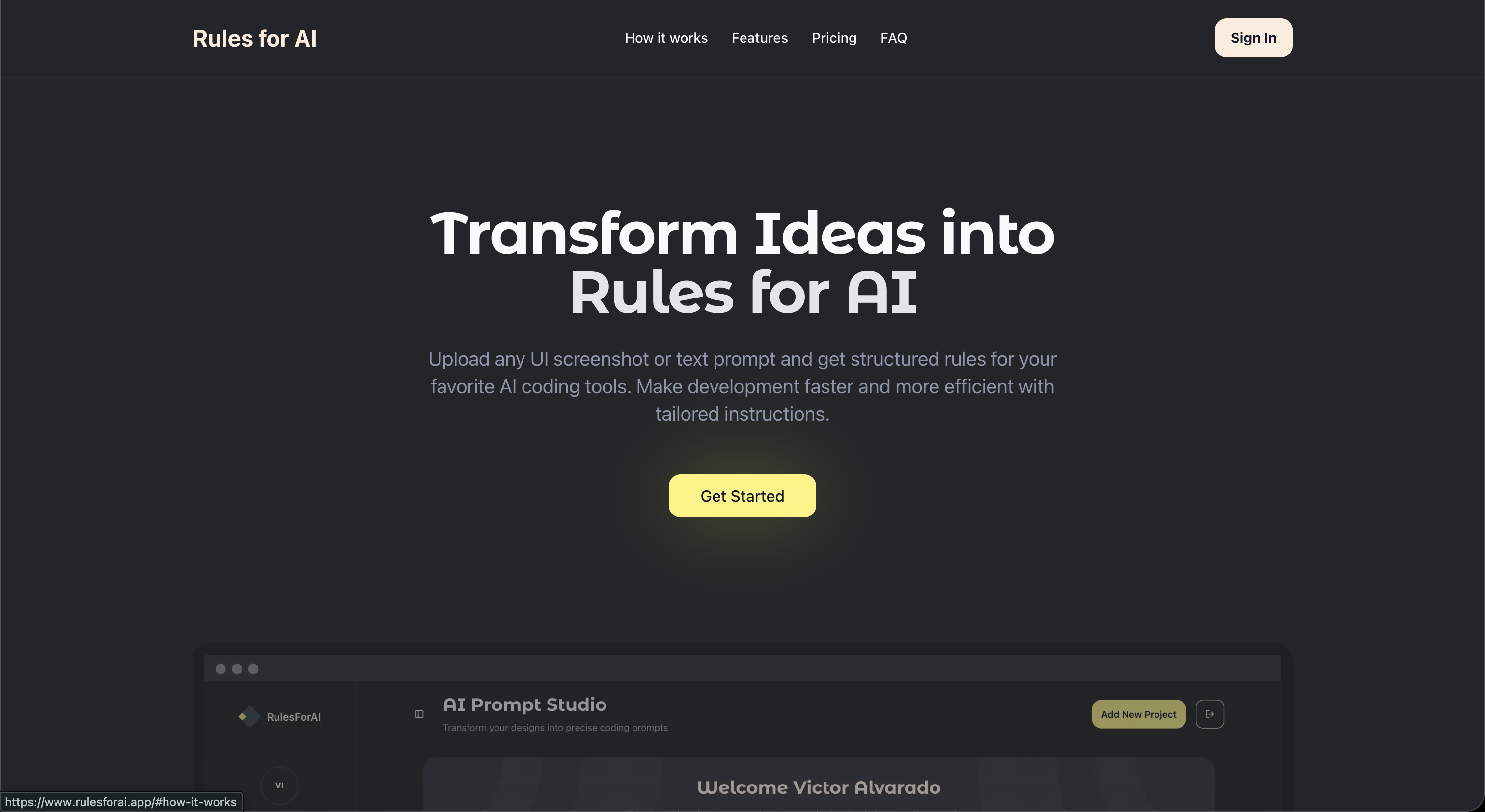
Problem
Developers adopting AI coding tools often face the same bottleneck: outputs are inconsistent because team standards and project constraints are not encoded clearly.
Common pain points:
- Prompt quality varied by person and by day.
- Important constraints (stack, architecture, style, security) were frequently omitted.
- Teams repeatedly rewrote similar instructions for every new project.
- AI outputs looked “technically correct” but misaligned with project conventions.
In short: teams had AI access, but not AI operational discipline.
Goals
- Make it easy to convert natural-language context into structured rule sets.
- Improve consistency and quality of AI-generated code outputs.
- Reduce setup time when starting new projects.
- Keep the UX simple enough for solo developers and small teams.
Solution
I designed RulesForAI around a guided generation flow:
- User provides project context (stack, architecture preferences, coding standards, constraints).
- The platform structures that context into a normalized format.
- The system generates reusable rules/skills optimized for coding agents.
- Users refine and export outputs for practical use in their workflow.
Key product choices:
- Prioritized clarity over feature bloat in early versions.
- Focused on structured outputs instead of generic long-form prompts.
- Built for repeatability, so users can start from reusable patterns, not blank pages.
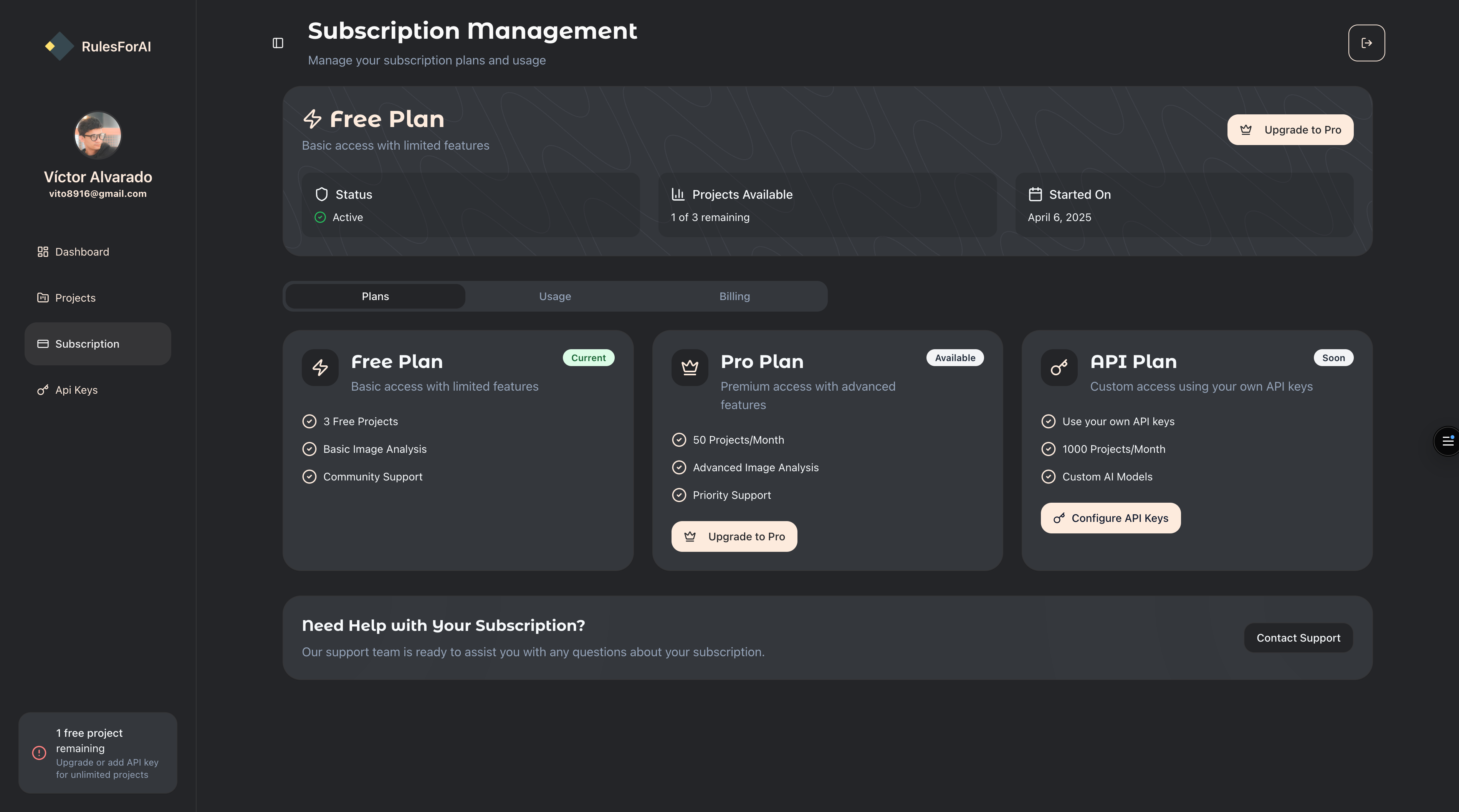
Dashboard
The cover image in the overview is one view of the product; below are four more dashboard screenshots from the same web app.
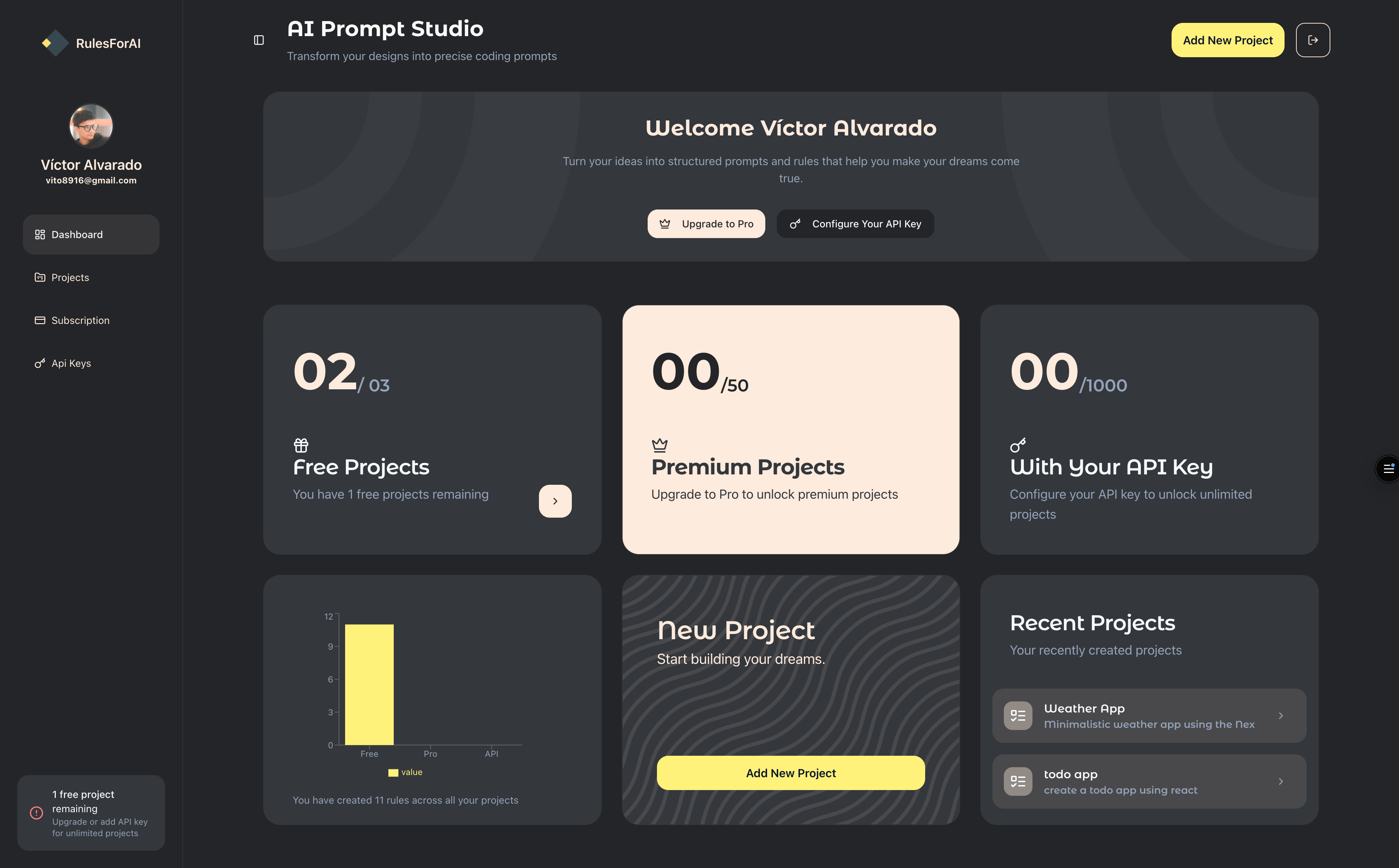
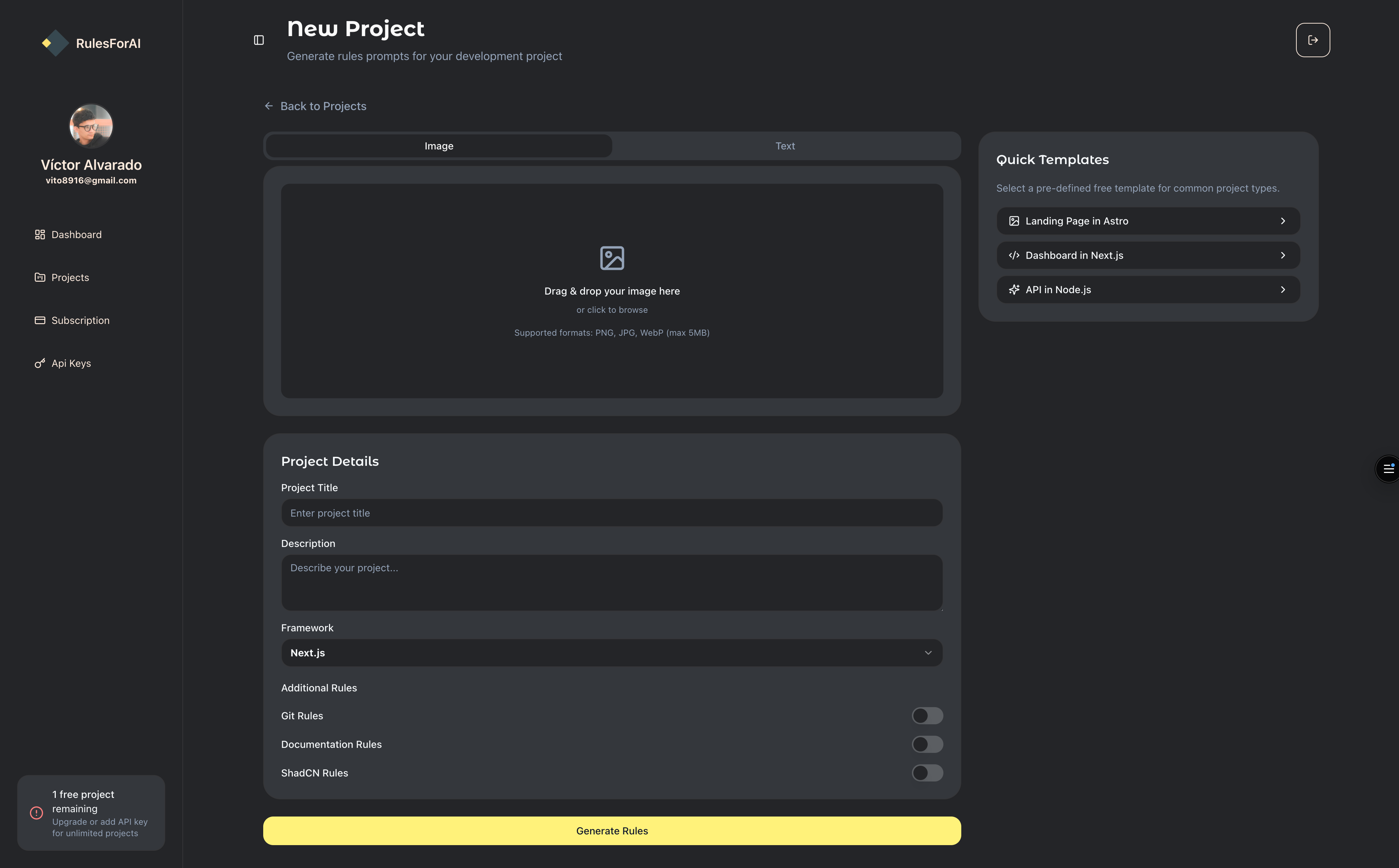
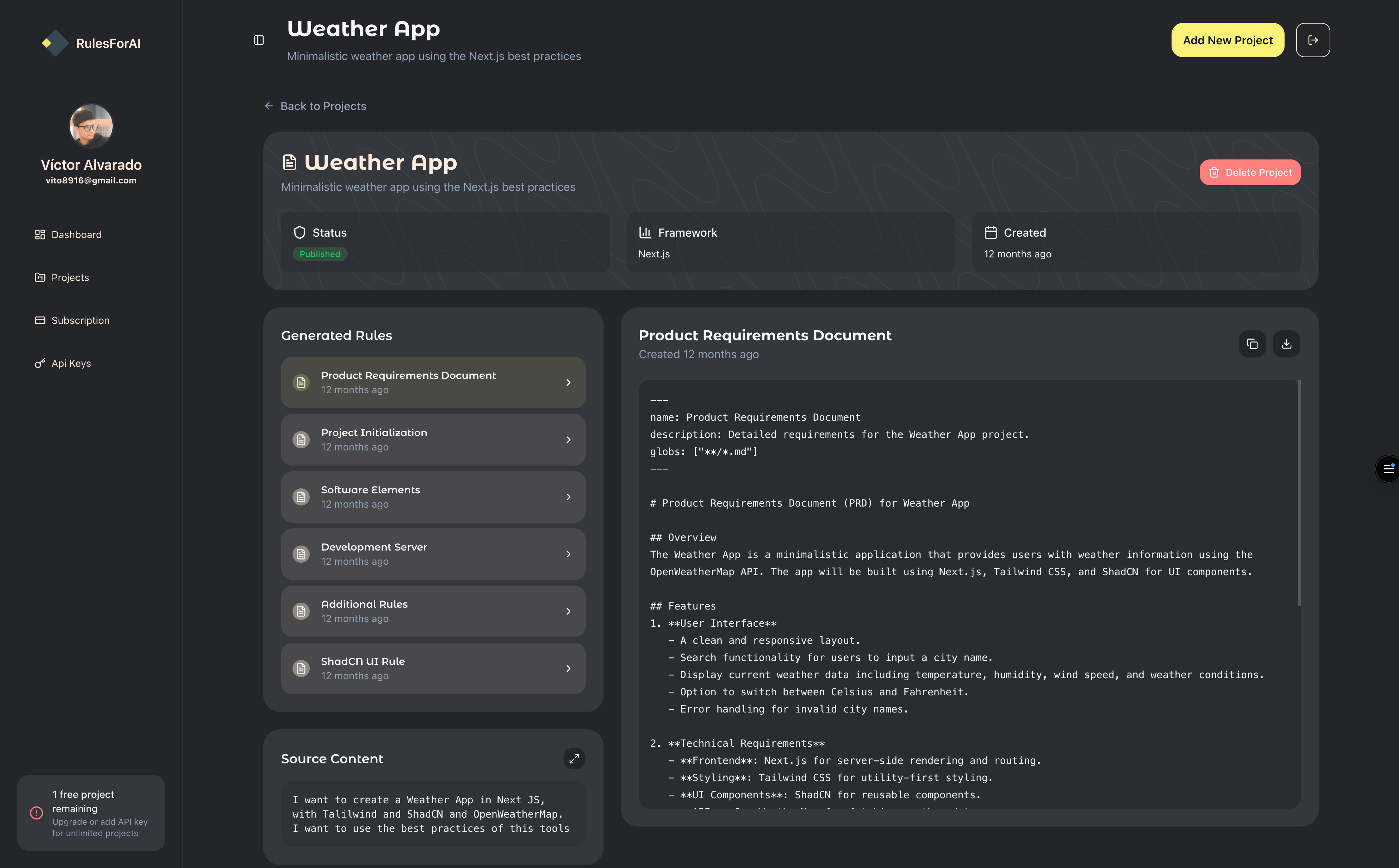
Tech highlights
Architecture
- Next.js application for fast iteration and a single deployment surface.
- Supabase + PostgreSQL for auth, persistence, and low operational overhead.
- OpenAI API for rule generation, called through a server-side orchestration layer.
- Stripe for subscription billing, gating access to paid features.
- Vercel for deployment.
Data model
Core entities:
- Project contexts
- Generated rule artifacts
- Reusable templates and patterns
- User-level organization of outputs
Product engineering decisions
- Kept schema and validation close to domain boundaries for safer evolution.
- Shipped incrementally to validate assumptions quickly.
- Optimized for maintainability and low operational complexity — one person had to run the whole stack.
Outcomes
- Live, solo-built SaaS — Next.js, Supabase, OpenAI, and Stripe, shipped by one person on 25 Feb 2025.
- 18 of 20 signups converted to paid — an unusually strong early conversion rate that validated the core problem for the users it reached.
- 100+ rule sets generated through the guided flow, proving the context → structured output loop worked end-to-end for real projects.
- Operational simplicity: Supabase managed auth and data, Stripe managed billing, OpenAI handled generation — so one person could actually run it.
Current status
RulesForAI is live but currently idle — no active users today. The engineering and monetization both worked; distribution for a solo indie product is the harder, still-unsolved part. The case study documents what was built, what was validated, and what the honest ceiling looked like at the solo stage.
Challenges
1. Prompt → structured output reliability
The defining technical problem was making an LLM produce well-formed, reusable rule artifacts instead of free-form prose. In practice this meant:
- Strict output schemas. Every generation path targeted a typed shape (rule fields, skill fields, metadata) — not a paragraph. Outputs that didn’t match the schema were rejected and retried rather than shown to the user.
- Validation at the boundary. Responses were parsed and validated server-side before persistence, so a malformed generation couldn’t corrupt a user’s project.
- Retry with tightening. On failed parses, the orchestration layer re-prompted with stricter framing and examples instead of failing loudly to the user.
- Concise over verbose. LLMs tend to pad. The prompting stack was tuned to produce operational rules — short, applicable, reusable — not essays that look impressive but no one actually uses.
Getting this loop reliable is what made the product feel like a tool instead of a prompt wrapper.
2. Balancing flexibility with structure
Too much flexibility produces noise; too much structure feels rigid. The guided inputs give users enough room to express project-specific constraints while keeping the output shape predictable.
3. Scope discipline
Solo products die from feature bloat. I kept the loop small — context in → structured rules out — and left adjacent features (team collaboration, versioning, quality scoring) on the roadmap rather than shipping shallow versions of everything.
What I’d improve next
- Team collaboration and versioning for rule sets.
- Export formats for more agent ecosystems (beyond the initial target).
- Quality scoring and validation checks before export.
- Onboarding presets by stack (e.g., Next.js + Supabase + Stripe).
- Distribution — the real lesson from the idle state: indie SaaS lives or dies on reach, not code.
Final takeaway
RulesForAI is an honest portrait of solo product engineering: a real workflow problem, a focused solution, a monetized shipping path, and a validated-but-idle current state. The craft — schema-enforced LLM outputs, clean domain modeling, a one-person stack that actually runs — held up; the distribution problem is the real lesson.